Developer Guide¶
alchemiscale is an open-source project, and we invite developers to contribute to its advancement and to extend its functionality.
This document provides some guidance on:
the system architecture, guiding philosophy for design choices
components and their technology stacks
the overall layout of the library
how best to engage with the project
System architecture and design philosophy¶
alchemiscale is an example of a service-oriented architecture, with the following components:
the system state represented in a graph database (Neo4j), often referred to as the state store
result objects (e.g. files) stored in an object store, such as AWS S3
user access to the state store and object store via a RESTful API (
AlchemiscaleAPI), often using the included Python client (AlchemiscaleClient)compute services deployed to resources suitable for performing free energy calculations, typically with GPUs for simulation acceleration
another RESTful API (
AlchemiscaleComputeAPI) used by the compute services for interaction with the state store and object store
These components function together to create a complete alchemiscale deployment.
They are shown together visually in Fig. 2.
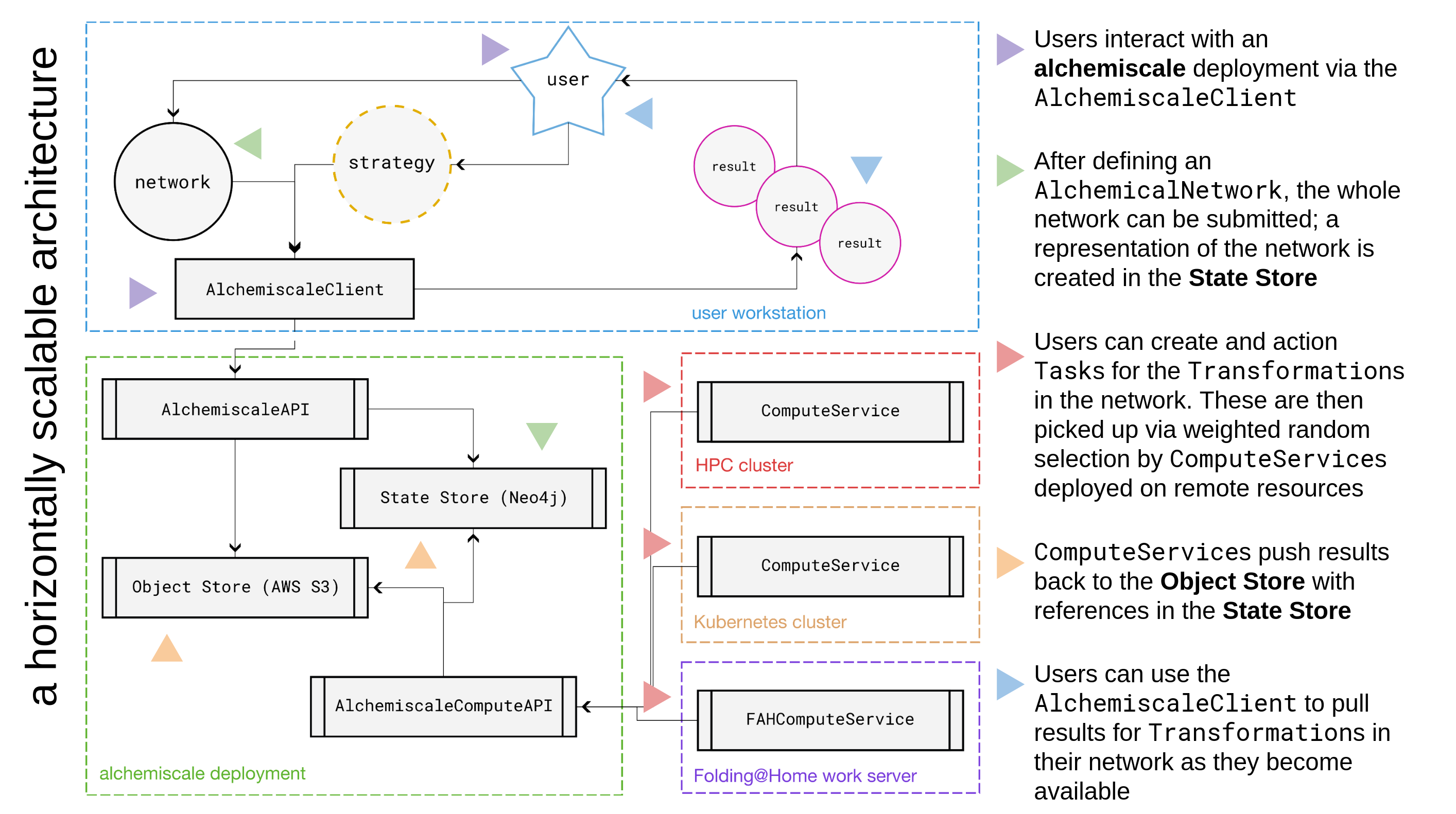
Fig. 2 Diagram of the system architecture for alchemiscale.
Colored arrows on the diagram correspond to descriptions on the right.¶
Components and technology stacks¶
Each component of alchemiscale makes use of an underlying technology stack specifically oriented to that component’s purpose and needs.
We detail these components in this section.
State store¶
The state store for alchemiscale represents the current state of the system at all times, without regard to the state of any other component.
It represents the single source of truth for what exists and what does not in the deployment, the status of running calculations, available results, etc.
Other components can experience failures and faults, but the content of the state store is the only content that really matters at any given moment.
We use a graph database, Neo4j, as the state store.
The choice of a graph database (over e.g. a relational database or a document database) was natural given the graph structure of AlchemicalNetworks,
which constitute the core data model alchemiscale operates on.
With Neo4j, it wasn’t necessary to contort these networks into relational tables or into loosely-related document records, and we can take advantage of deduplication of network nodes where appropriate for database performance and efficient use of compute resources.
The Neo4jStore class is alchemiscale’s interface to its Neo4j instance, and broadly defines the interaction points for the state store.
The methods on this class interact with Neo4j via py2neo, a client library that features a flexible object model for defining complex networks in Python and representing them in Neo4j.
Neo4j itself uses Cypher as its query language, and this is used throughout the Neo4jStore for modifying the state of the nodes and edges in the database.
It is worth reviewing the Cypher manual if you wish to make contributions to alchemiscale that require new interactions with the state store.
Object store¶
The object store is used for result storage.
Execution of Tasks by Compute services yields ProtocolDAGResult objects, and these are stored
in a directory-like structure within the object store for later retrieval.
References to these objects are created in the state store, allowing the state store to function as a fast index for finding individual results on request.
When a user makes use of the AlchemiscaleClient to request results for a given Transformation, the AlchemiscaleAPI queries the state store for these references, then pulls the corresponding results from the object store and returns them as responses to the request.
The choice of object store corresponds to the platform alchemiscale is being deployed to.
Currently, there is only one implementation, using AWS S3 as the object store, but there are plans to create implementations appropriate for other cloud providers, as well as to provide a “local” object store for single-host deployments.
For the AWS S3 object store, alchemiscale makes use of S3ObjectStore as its interface.
This object provides methods for storing and retrieving ProtocolDAGResults, and over time will support methods for storage of arbitrary files as required by certain Protocols.
RESTful APIs¶
A complete alchemiscale deployment (currently) features two RESTful APIs, which handle HTTP client requests:
AlchemiscaleAPI: handles requests from user identities; includes submittingAlchemicalNetworks, actioningTasks, and retrieving resultsAlchemiscaleComputeAPI: handles requests from compute identities; includes claimingTasks, submitting results on completion or failure
All API services in alchemiscale are implemented via FastAPI, and deployed as Gunicorn applications with Uvicorn workers.
These services are “stateless”: they modify the state of the state store and object store, but the state of the service workers themselves is ephemeral and relatively disposable.
Workers can be scaled up or scaled down to handle more or fewer requests from clients, but this has no bearing on the overall state of the alchemiscale deployment.
By construction, these API services can be horizontally scaled across many physical servers, and need not be co-located with the state store. This is the approach taken, for example, when deploying to Kubernetes via alchemiscale-k8s.
User-facing Python client¶
Users interact with an alchemiscale deployment via the Python client AlchemiscaleClient.
This client allows users to directly use Open Free Energy ecosystem tools to define AlchemicalNetworks, then submit, execute, and retrieve results for those networks via alchemiscale, all from within a single Python session.
The client methods convert Pythonic user input into HTTP requests to the AlchemiscaleAPI, which services those requests and issues responses, which are then converted by the client back into Pythonic objects.
The client automatically handles authentication, including JWT retrieval and refreshes, as well as retries due to unreliable network connections, overloaded or temporarily-unreachable API services, etc.
Some methods also make use of asyncio for requesting many entities in concurrent calls, and/or performs batching of calls for many entities.
Internally, the requests and httpx libraries are used for making HTTP requests, for synchronous and asynchronous calls, respectively.
Although it is possible to interact with the AlchemiscaleAPI with requests using any HTTP client, including e.g. curl, this is not generally recommended for users.
Compute services¶
Compute services are deployed and run on resources suitable for executing actual free energy calculations.
They are not considered part of the “server” deployment, which includes the state store, the object store, and the API services.
Compute services are designed to be run independently of one another, and function as clients to the AlchemiscaleComputeAPI.
There currently exists a single implementation of an alchemiscale compute service: the SynchronousComputeService.
This functions as the reference implementation; other variants will likely be created in the future, optimized for different use cases.
The discussion that follows describes the behavior of compute services in general, and should apply to all variants.
When a compute service is started, it consumes a configuration file for setting its parameters, such as this template configuration for the SynchronousComputeService,
This file sets the URL for the target alchemiscale instance, compute identity and key, and any parameters specific to the resource on which the compute service is deployed.
See Compute for additional details on deployment.
After starting up, the compute service registers itself with the AlchemiscaleComputeAPI, creating a ComputeServiceRegistration instance in the state store.
It will then claim Tasks for execution, pull the corresponding Transformation, create and execute a ProtocolDAG, and push the corresponding ProtocolDAGResult back to the AlchemiscaleComputeAPI upon completion or failure.
The compute service will continue this behavior until it reaches a configured stop condition, receives a termination signal, or is killed.
The compute service periodically issues a heartbeat to the AlchemiscaleComputeAPI, updating its last known heartbeat datetime in its registration.
If the compute service is killed without a chance to deregister itself, its heartbeat won’t be updated, and eventually the registration will be expired and deregistered by the AlchemiscaleComputeAPI.
If the compute service reaches a configured stop condition or receives a termination signal, it will cease execution, deregister itself, and shut down.
Deregistration automatically unclaims any "running" Tasks and sets their status back to "waiting".
Compute services make use of the AlchemiscaleComputeClient for issuing all requests and handling responses from the AlchemiscaleComputeAPI.
This is directly analogous to the way users interact with alchemiscale via the AlchemiscaleClient through the AlchemiscaleAPI.
Like the AlchemiscaleClient, the AlchemiscaleComputeClient automatically handles authentication and JWT refreshes, retries, etc.
Library layout¶
The alchemiscale codebase is generally organized according to the components detailed above.
At the top level of the source tree, we have:
modelscommon
alchemiscaledata models, in particularScopeandScopedKeysettingssettings data models for configurable components
clicommand-line interface, implemented via click
storagestate store and object store interfaces, along with relevant data models; not user-facing
basebase classes and common components for RESTful APIs, HTTP clients
interfaceuser-facing
AlchemiscaleClientandAlchemiscaleAPIdefinitionscomputecompute-facing
AlchemiscaleComputeClientandAlchemiscaleComputeAPI, as well as compute service classessecuritydata models and methods for defining credentialed identities and authenticating them, implementation of JWT via jose
testsintegration and unit test suite; implemented via pytest, and utilizes Docker via grolt for Neo4j testing
Other modules, such as strategist and strategies, are currently placeholders for future functionality.
See the API Reference for the detailed contents of each of these modules.
How to contribute¶
Interested in helping to develop alchemiscale?
The project is developed openly on GitHub, and the best way to get started is to introduce yourself in our New Contributors Discussions tab.
We can help orient you to problems aligned with your interests and skills from there!
Before you start work on a new feature, it’s a good practice to first open an issue describing it.
This allows the maintainers to respond to your desired feature and offer guidance on how to go about implementing it, or whether it is within scope of the project’s vision.
It may be that the feature you are after already exists in some form, isn’t really possible given alchemiscale’s architecture, or isn’t actually desirable for one or more reasons.
Starting the discussion in an issue is likely to save you time, energy, and possibly frustration, so please take a moment to describe what you are after before working to implement it.
The issue also functions as a convenient anchor point for maintainers to triage feature requests, perhaps grouping them with others in an upcoming milestone.
If the feature is of broad interest, or of interest to the maintainers themselves, you may find you don’t have to implement it at all!
Setting up your development environment¶
If you’ve decided to work on some aspect of alchemiscale, the development workflow is roughly as follows.
It’s recommended that you develop/test on a Linux host, as there are known issues with developing on Mac.
To develop new features, fix bugs, and advance the alchemiscale codebase, you will need to:
Clone the repository to your local machine:
$ git clone git@github.com:OpenFreeEnergy/alchemiscale.git $ cd alchemiscale
Create a conda environment for running the test suite, preferably with mamba, and activate it:
$ mamba env create -n <environment-name> -f devtools/conda-envs/test.yml $ conda activate <environment-name> .. note: To run integration tests, you will need to have ``docker`` installed and executable without ``sudo``. See `Manage Docker as non root-user`_ for more information.
Perform an editable install of the
alchemiscalesource tree:$ pip install -e .
Make changes to the codebase, add or modify tests where necessary, then run the test suite:
$ pytest -v alchemiscale/tests
Address test failures. Once clear, commit your changes on a new branch:
$ git checkout -b <feature-branch-name> $ git commit -a -m <commit-message>
Create a pull request (PR) from your own fork; this is easiest with the GitHub CLI:
$ gh pr create
Once your PR is up, a maintainer can review it and offer feedback. It is unlikely that your PR will be merged immediately; it is often the case that changes will be requested to conform the feature to current patterns in the codebase, improve its maintainability, etc. Please be patient, and understand that it may take some time (weeks, even months) between the time a PR is created, accepted, and merged.